Introducción
En una incidencia crítica, el problema no es solo técnico. Es el caos: quién decide, quién comunica, qué se toca primero y cómo se vuelve a un estado estable.
Un runbook sirve para reducir esa incertidumbre. Lo interesante aquí es que no tiene que ser perfecto; tiene que ser accionable bajo presión.
Vamos a ver qué es un runbook, cómo diseñarlo y qué detalles marcan la diferencia cuando todo va rápido.
Qué es un runbook de incidencias
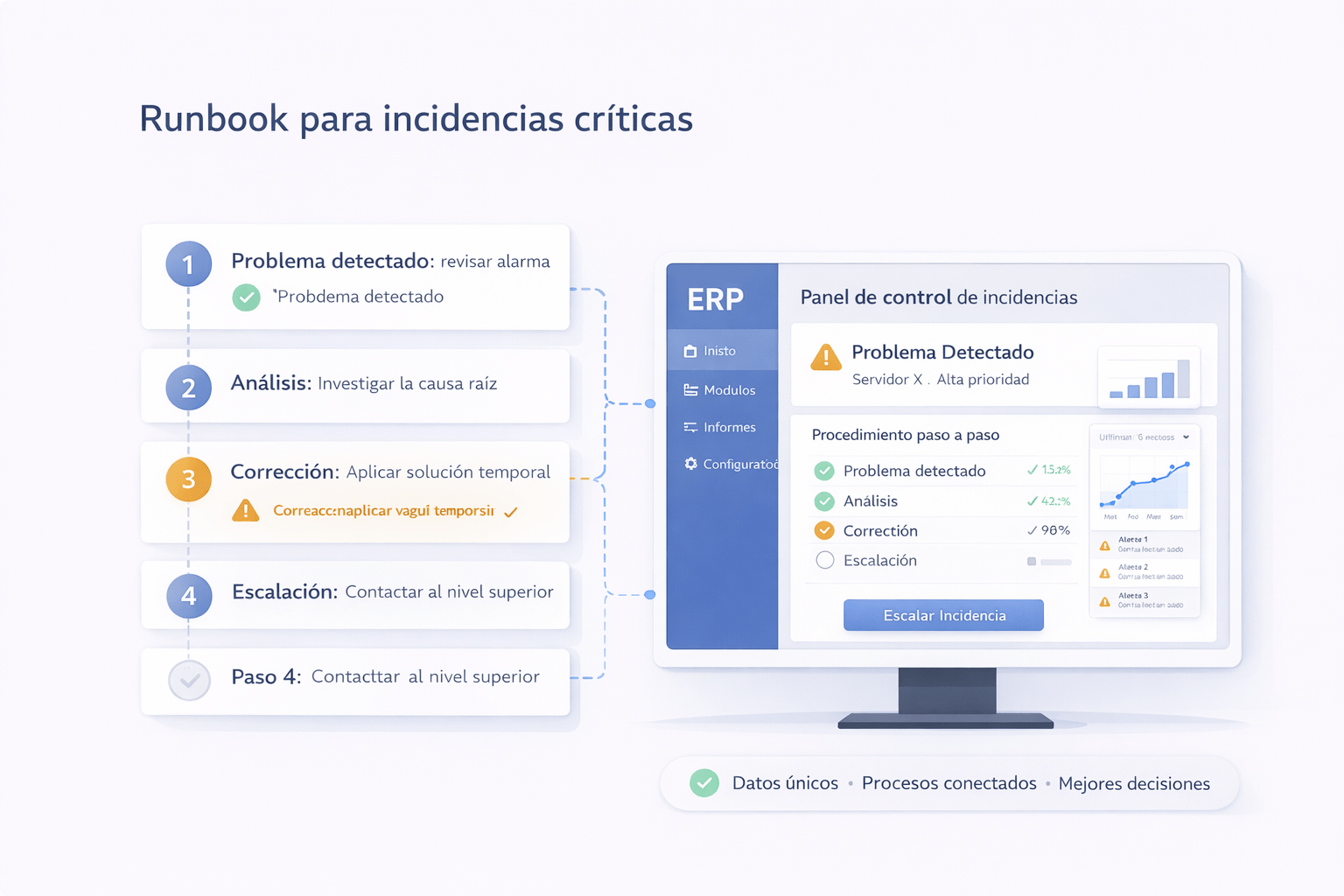
Un runbook es un procedimiento paso a paso para responder a un tipo de incidencia: caída de servicio, degradación, compromiso de cuenta, fallo de backup, etc.
Dicho de otro modo, es memoria externa del equipo. Define activación, roles, acciones y validación sin depender de «quién se acuerda».
No se trata de escribir un documento largo, sino de capturar lo que realmente se necesita: criterios de severidad, accesos, pasos y comunicación.
Por qué es relevante
Es relevante porque reduce MTTR y evita errores en caliente. Cuando el equipo improvisa, suele repetir los mismos pasos y perder minutos valiosos.
Además, un runbook mejora coordinación con negocio: define qué se comunica, a quién y cuándo. Eso reduce ansiedad y decisiones contradictorias.
Desarrollo principal
Empieza delimitando alcance: qué cubre y qué no cubre. En la práctica, un runbook demasiado genérico no ayuda cuando hay que elegir.
Define criterios de activación y severidad. Lo interesante aquí es que, sin umbrales, todo parece urgente y nada se gestiona bien.
Asigna roles: commander, técnico principal, comunicaciones y enlace con negocio. No se trata de jerarquía, sino de evitar bloqueos por responsabilidad difusa.
Describe acciones en orden: contención, diagnóstico, mitigación, recuperación y validación. Cada paso debe indicar qué evidencia recoger para el postmortem.
Incluye rutas de comunicación y plantillas simples: estado, impacto y siguiente actualización. En crisis, escribir desde cero cuesta.
Entrena el runbook con ejercicios cortos. Después de cada incidencia o simulacro, actualiza: un runbook vivo vale; uno viejo confunde.
Desglose práctico
Para caída total, define un primer bloque de comprobaciones rápidas: dependencias, monitorización y cambios recientes. Dicho de otro modo, evita saltar directo a reiniciar sin saber qué pasó.
Para degradación, incluye cómo medir: latencia, errores y saturación, y qué umbrales justifican activar modo degradado o deshabilitar funciones.
Para cuentas comprometidas, describe pasos de contención: revocar sesiones, reset, revisar MFA y comprobar reglas de reenvío. Lo interesante aquí es actuar sin borrar evidencia.
Y para backups, indica cómo restaurar y validar con negocio. En la práctica, una restauración sin validación funcional es un espejismo.
Limitaciones o consideraciones
Un runbook no cubre lo desconocido. Si la arquitectura cambia, el procedimiento puede quedar obsoleto.
También puede ser demasiado rígido. No se trata de seguirlo como receta, sino de usarlo como guía para decidir más rápido.
Y requiere accesibilidad: debe estar disponible incluso si cae el sistema habitual. Tenerlo solo en una wiki interna que se cae con el servicio es un clásico.
Conclusión con visión de futuro
Un runbook efectivo convierte una incidencia en un proceso controlado: roles claros, pasos ordenados y comunicación consistente.
A futuro veremos más runbooks como código, automatización y ChatOps. Pero el valor seguirá siendo el mismo: claridad bajo presión.